Obtención de los datos
Las audiencias públicas de causas nacionales se suben en formato de video a YouTube, al canal del Poder Judicial: https://www.youtube.com/@pjn-videoconferencias. Estos videos fueron descargados tal cual están subidos a dicho canal, luego se obtuvo en formato .mp3 el audio sin video y finalmente mediante ffmpeg se convirtieron a .wav. Al final del proceso se obtienen todos los archivos de interés en formato wav
Creación de las transcripciones
Este proceso require varios pasos puesto que no hay herramientas actuales que de forma autónoma puedan detectar los nombres de las personas que hablan a través de varios videos. Este tipo de herramientas podrían crearse con la tecnología actual y esto se debate en la sección Trabajo futuro.
Transcribir el audio
Existen modelos de transcripción de audio cuyo único propósito es convertir un audio a texto (Speech To Text o STT). Estos modelos son útiles para su único propósito que es responder a "¿Qué se dijo?" pero inútiles para determinar quién dice qué. Por ejemplo, véase el siguiente audio
La transcripción según el modelo de whisper-large-v2 es
whisper.exe .\sample.wav --language es
[00:00.000 --> 00:03.500] No sé si prendieron el aire acondicionado.
[00:04.820 --> 00:08.220] A ver, puede ser, puede ser que hayan prendido el aire acondicionado.
Como se puede apreciar, el modelo Whisper no está hecho para detectar que estas dos frases fueron pronunciadas por personas distintas, sino que simplemente transcribe lo que se dijo. Adicionalmente, el modelo no detectó la palabra inicial "Doctor" del momento en el cual la Jueza le da la palabra al abogado.
La transcripción del audio no es perfecta. Es importante tener esto en cuenta para reproducir, distribuir y consumir estos datos de forma responsable. Es por esto que a las descargas en esta página siempre las van a preceder un aviso de precaución.
Diarización del audio
El proceso de detectar "¿Quién dijo qué?" se llama diarización. Es un proceso que busca encontrar patrones de voces y asignarles un número, de forma tal que la misma voz (idealmente) tendrá el mismo identificador. Es importante entender que este proceso no responde a la pregunta de "¿Cómo se llama la persona que dijo..?" puesto que eso require un entendimiento del lenguaje superior. Los modelos de diarizacción no tienen conocimiento sobre qué se dice, sino que simplemente detectan cambios de voz. Por ejemplo, para el mismo audio tenemos el siguiente output usando el modelo pyannote/speaker-diarization-3.1
start=0.0s stop=0.6s speaker_SPEAKER_00
start=1.1s stop=3.6s speaker_SPEAKER_00
start=4.8s stop=5.3s speaker_SPEAKER_01
start=5.4s stop=8.3s speaker_SPEAKER_01
Notar la siguiente visualización de la forma de onda del audio

Se pueden ver los silencios detectado por la IA, así como también que el SPEAKER_00 habla en dos tramos de 0 a 0.6 y 1.1 a 3.6, y el SPEAKER_1 de 4.8 a 5.3 y 5.4 a 8.3
Sin embargo, esto es incorrecto, como indicamos antes el primer tramo (0.0 a 0.6) es la palabra "Doctor" pronunciada claramente por la voz femenina que corresponde a la Jueza y el siguiente tramo (1.1 a 3.6) pertenece a la voz masculina preguntando por el aire acondicionado.
La dirazación del audio no es perfecta. Es importante tener esto en cuenta para reproducir, distribuir y consumir estos datos de forma responsable. Es por esto que a las descargas en esta página siempre las van a preceder un aviso de precaución.
Alineamiento forzado
La transcripción nos indica cuando empieza y termina cada frase y la diarización cuando empieza y termina cada voz (con algunos errores). Lo que queda es alinear estos inicios entre estas dos IAs de forma que podamos asignar una voz a una frase. Manualmente esto sería ver que si el SPEAKER_0 inició a hablar en 0.0, luego terminó en 3.6 entonces es razonable pensar que la frase No sé si prendieron el aire acondicionado que inicia en 0.0 y termina en 3.5 debe haber sido pronunciada por SPEAKER_0 (todavía no sabemos cómo se llama, eso viene después). El alineamiento forzado es simplemente obtener el inicio y fin más próximo de una frase con su voz y asignarle dicha voz a esa frase. Entonces tendríamos algo como
whisperx '.\sample.wav' --model large-v2 --diarize --language es
00:00.000 --> 00:03.500
[SPEAKER_0] No sé si prendieron el aire acondicionado.
00:04.820 --> 00:08.220
[SPEAKER_1] A ver, puede ser, puede ser que hayan prendido el aire acondicionado.
Esta operación es exactamente la que hace whisperX, un programa de código abierto creado por el usuario m-bain.
Ponerle un nombre a la voz
Una forma sencilla de lograr esto sería manualmente abrir cada archivo, verificar que SPEAKER_0 es la Jueza Sabrina Namer y simplemente hacer un macro reemplazo en todo el archivo. Si bien esto puede funcionar, no es escalable a todas las causas judiciales y ni siquiera a distintos archivos de la misma causa. SPEAKER_0 en este caso se llama asi porque fue el primero que el proceso de Diarización detectó, pero en otro archivo la misma voz podría estar asignada a otro número.
Lo que necesitamos entonces es verificar la similitud de esa voz (de la cual podemos obtener un extracto, porque sabemos cuando empiza y termina) respecto de una base que ya tengamos validada. Es decir, deberíamos obtener algunos audios que estemos absolutamente seguros que pertenecen a una persona en específico y comparar dicho audio con el extracto del cual tenemos dudas. Para esto podemos usar embeddings
Embeddings
Los embeddings son representaciones vectoriales de cosas, cualquier cosa. Sin embargo, representar algo como un vector arbitrario no tiene mucho uso ni sentido, sino que es necesario que dicho vector sea comparable con otros vectores en alguna dimensión que sí sea útil. El ejemplo más clásico de esto es imaginarse un plano de puntos donde cada punto es una palabra y la cercanía entre puntos sea la similitud semántica de las palabras de forma tal que la palabra "Gato" esté cerca de la palabra "Animal" o "Rey" esté cerca de "Reina" puesto que son palabras que se usan en contextos similares
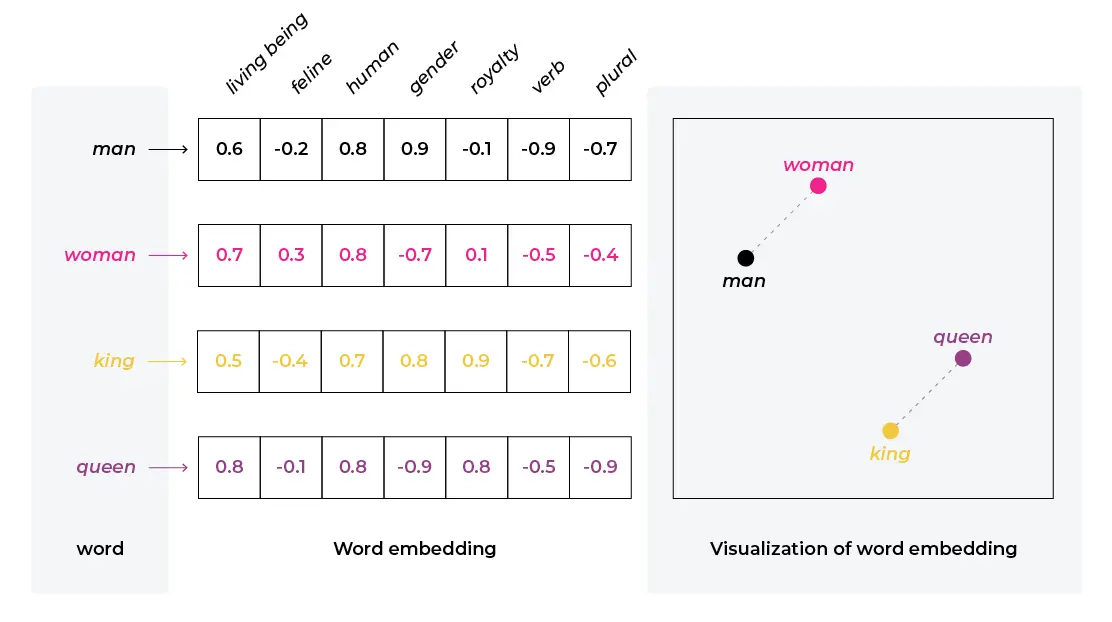
Seguro el lector puede inferir que usar solamente dos dimensiones para determinar si una palabra es "semánticamente similar" a otra es una sobresimplificación, puesto que el contexto en el cual se usa una palabra es vital. Decirle "Rey" a una persona con el título de nobleza tiene más similitud semántica con "Su majestad" o "Su excelencia" comparado a decirle "Rey" a tu amigo que lleva coronita, en cuyo contexto tendría más similitud semántica con "Amigo". Esta variación se puede también representar utilizando mayor dimensionalidad, por ejemplo poniendo nubes de puntos en 3 variables en un espacio tridimensional en lugar de un plano. Los modelos de lenguaje generalmente hacen estos embeddings en 1024 a 2048 dimensiones distintas.
Esto mismo se puede hacer con audios, de forma que un extracto de un audio se puede mapear a un espacio vectorial tal que los audios "similares" estén más "cerca". El uso de las comillas es intencionado, pues que un audio esté más "cerca" de otro audio o más "lejos" excede la representación clásica de distancias lineales. Particularmente, los embeddings de audio que usamos tienen 512 dimensiones por lo que no se pueden representar en un plano. Además en nuestro caso cuando hablemos de distancia vamos a hablar de distancia coseno que es la diferencia angular entre dos vectores, por ejemplo la distancia coseno entre tu dedo Pulgar e Índice es probablemente mayor a la distancia coseno entre tu dedo Índice y dedo Mayor porque el ángulo que los separa es más grande cuando tu mano está abierta. En análisis de ondas se usa la distancia coseno porque la distancia lineal aumenta con el volumen, y una voz es la misma independientemente de que tal alto se escuche.
Podemos entonces armarnos una base de datos con extractos de voces conocidas y asignarles un nombre a cada una. Esto es un proceso manual pero que se puede mejorar a si mismo, por ejemplo si manualmente indico que un extracto pertenece a Cristina Fernandez de Kircher y más adelante encuentro un extracto cuya similitud es muy alta, entonces puedo calcular el embedding de dicho extracto y también asignarselo a la misma persona.
Base de datos de embeddings
Hay varias implementaciones de bases de datos que permiten almacenar embeddings y ejecutar reconocimientos de similitud entre ellos. En nuestro caso usamos PostgreSQL con la extensión pgvector la cual tiene librerias disponibles en Python para automatizar su uso
class Voice(SQLModel, table=True):
id: int = Field(primary_key=True)
name: str # Nombre de extracto
label: str # Nombre de la persona
embedding: Any = Field(sa_column=Column(Vector(512))) # Embedding de 512 dimensiones
def insert_if_not_exists(name: str, label: str, embedding: ndarray):
result = session.exec(select(Voice).filter(Voice.name == name)).first()
if result is None:
insert_item(name, label, embedding)
def get_nearest_items(target: ndarray, limit: int = 5, threshold: float = 0.5):
result = session.exec(
select(Voice, Voice.embedding.cosine_distance(target.tolist()).label('distance'))
.filter(Voice.embedding.cosine_distance(target.tolist()) <= threshold)
.order_by(Voice.embedding.cosine_distance(target.tolist()))
.limit(limit)
)
return result.all()
Mientras procesamos un archivo podemos obtener su embedding usando pyannote/embedding
model = Model.from_pretrained("pyannote/embedding", use_auth_token=hf_token)
def generate_embedding(wav_file_path, start_time_s, end_time_s):
if end_time_s - start_time_s < 1: # Si el audio es menor a 1 segundo no se puede generar su embedding
return np.zeros(512)
inference = Inference(model, window="whole")
inference.to(torch.device("cuda"))
excerpt = Segment(start_time_s, end_time_s)
embedding = inference.crop(wav_file_path, excerpt)
return embedding
La distancia coseno es mayor cuando más disimilares son, es decir dos voces idénticas dan 0 y una voz respecto de ruido debería dar 1.
Con esta automatización y un poco de ayuda del usuario, podemos "enseñar" a la base de datos quién es cada persona con un diagrama de flujo como el siguiente
Este diagrama es perfecto en teoría pero no en práctica. Muchas veces hay fragmentos de voces superpuestas, o muy bajas, o simplemente silencios detectados por error como una voz distinta. En estos casos la distancia coseno va a ser altísima (muy disimilares) y realmente no queremos guardar dicho segmento como perteneciente a alguna voz. Por lo tanto, hay que darle al usuario la posiblidad de saltearse dicho segmento y dejarlo sin asignar. Estos son los casos en los que las transcripciónes quedan como "SPEAKER_XX" o los anotamos como "SEGMENTO MUY CORTO PARA ANALIZAR".
Voces nuevas
En un juicio oral hay muchas voces nuevas constantemente, cada testigo es una voz que no va a ser reconocida por el sistema (y correctamente) la cual se le va a tener que asignar. Por suerte, es parte del protocolo judicial preguntar al testigo su nombre y apellidos completos antes de iniciar el interrogatorio, véase la siguiente transcripción
17
00:02:33,234 --> 00:02:38,236
[SPEAKER_31]: Le pregunto entonces si jura o promete acuerdo a sus creencias, decir la verdad sobre aquello que supiera y le fuera
18
00:02:43,169 --> 00:02:44,552
[SPEAKER_31]: Juro.
19
00:02:45,153 --> 00:02:47,217
[SPEAKER_31]: Dígame por favor su nombre de apellido completo.
20
00:02:49,060 --> 00:02:50,303
[SPEAKER_11]: Ríos Rubén Marcelo.
De este extracto podemos deducir que SPEAKER_31 es un juez y SPEAKER_11 un testigo llamado Ríos Rubén Marcelo, sin embargo obtener todas las diferentes combinaciones posibles de la pregunta por nombre y apellido no sólo no es trivial, sino que es imposible con expresiones regulares porque el Español (ni ningún lenguaje humano) no es un lenguaje regular. Parece ser tentador buscar la cadena de texto nombre y apellido completo y asumir que la siguiente cadena de texto es el nombre del testigo. Esto sería un error por varios motivos, el primero está en la transcripción, notar que el modelo de transcripción detectó que se dijo "nombre de apellido completo", esto es probablemente por un error del modelo de transcripción pero ya muestra las falencias de usar expresiones regulares. Añadido a esto hay otros numerosos problemas como testigos no entendiendo las preguntas, hablando encima del juez, respondiendo antes de que termine de hablar el juez; etc.
Estos casos fueron resueltos por intervención humana. Cada vez que se detecta una nueva voz, se pregunta a un humano (quien les escribe) el nombre de la nueva voz. Para esto hicimos un programa en python con una simple interfaz de usuario que permite extraer todas las frases pronunciadas por esa voz de forma tal de poder identificar quien habla
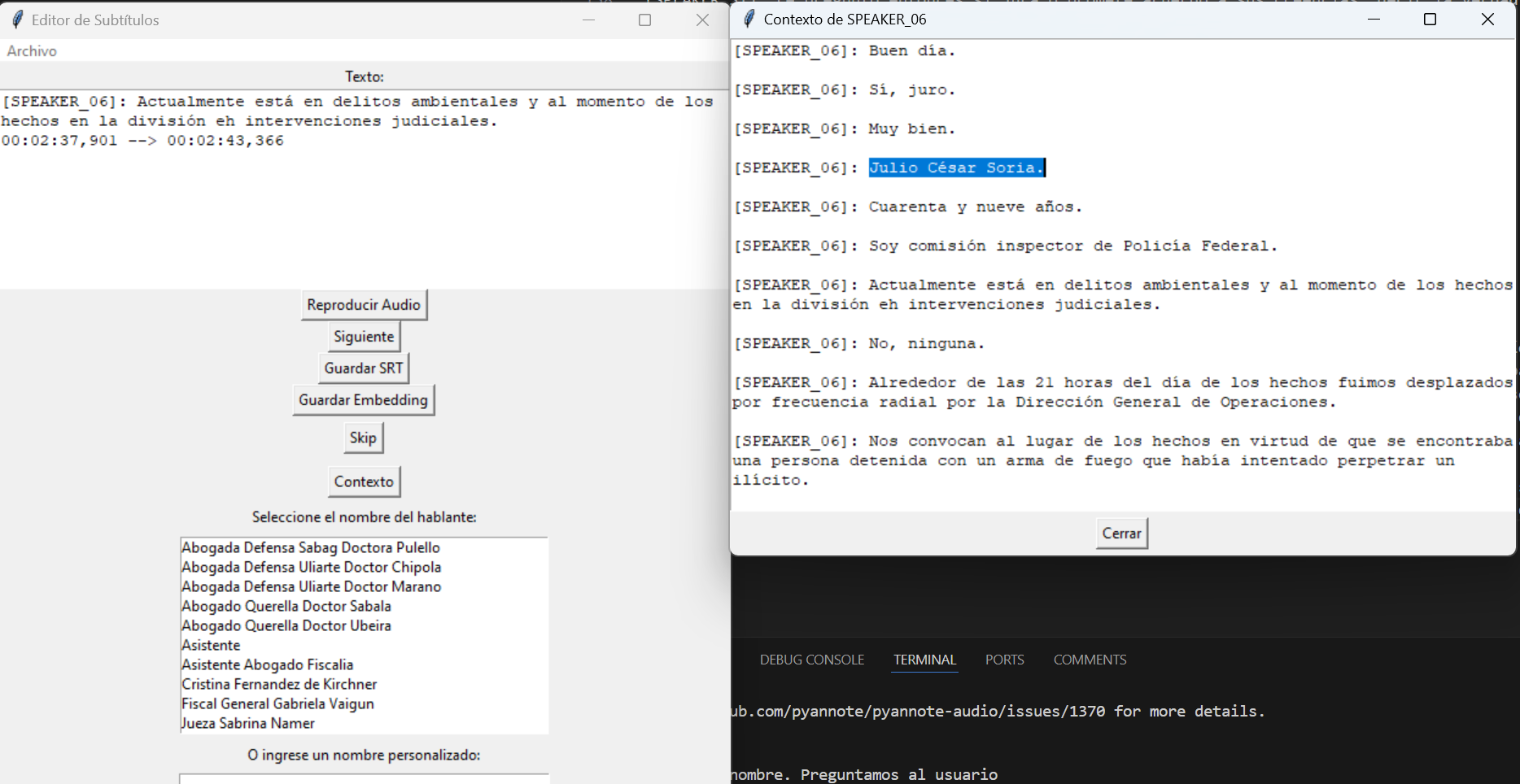
Una vez el usuario identifica la voz, esta puede mantenerse en memoria para futuros reconocimientos.
No se obtuvo el nombre. Preguntamos al usuario // El usuario ingresa Julio César Soria
Se obtuvo el nombre del embedding: Julio César Soria. // Se reconoció automáticamente en el siguiente extracto
Notar que hay voces comunes también que se van a repetir durante todo el transcurso del juicio, como las voces de los jueces, abogados, fiscales y otros funcionarios públicos. Estas son las más sencillas de reconocer puesto que hay cientos de extractos distintos para entrenar al modelo. Aún así, también puede suceder que por la enorme cantidad de ejemplos se guarden algunos outliers que no son representativos, como extractos donde la voz está muy baja, muy alta, saturada, enferma; etc. Estos outliers podrían luego por error ser asignados a testigos, por lo que una revisión humana es necesaria.
Conclusiones
Este proceso permite subtitular cualquier video, no sólo aquellos de causas judiciales, utilizando feedback humano para crear una base de conocimiento de voces reconocidas, un proceso similar al que se usa en reconocimiento de textos llamado "RLHF" o "Reinforcement Learning from Human Feedback" o "Aprendizaje Reforzado a partir de Información Humana". Puede ser una técnica fundamental para fomentar un gobierno más abierto y la facilidad de acceso a los datos del Poder Judicial, así como de cualquier otro evento público que se grabe en cualquier formato.
El proceso require intervención humana lo cual puede ser costoso y agrega sesgos al resultado final el cual ya está sesgado por las múltiples partes imperfectas que lo componen, como la transcripción automática y la dirización. La herramienta que usamos permitió en menos de 1 hora de trabajo humano generar las transcripciones de todas las audiencias a la fecha 10 de Noviembre de 2024 de la causa caraturalada como "Sabag Montiel, Fernando André y otros s/ homicidio agravado", las cuales suman un total de 37 horas y 45 minutos o 411.554 palabras. De acuerdo a una búsqueda de 30 segundos en Google, la escritura de un mecanógrafo promedio es de 52,2 palabras por minuto y están en el top 8% de escritores más veloces. A dicha velocidad, un mecanógrafo tardaría 132 horas en transcribir el texto a lo cual habría que sumársele las etiquetas de las personas que hablan.
Trabajo futuro
La parte manual de nuestro trabajo podría automatizarse aún más con un modelo de lenguaje como GPT, Llama o Phi al cual se podría enviar la transcripción y pedir que devuelva los nombre que deduce. Por ejemplo para el siguiente extracto
17
00:02:33,234 --> 00:02:38,236
[SPEAKER_31]: Le pregunto entonces si jura o promete acuerdo a sus creencias, decir la verdad sobre aquello que supiera y le fuera
18
00:02:43,169 --> 00:02:44,552
[SPEAKER_31]: Juro.
19
00:02:45,153 --> 00:02:47,217
[SPEAKER_31]: Dígame por favor su nombre de apellido completo.
20
00:02:49,060 --> 00:02:50,303
[SPEAKER_11]: Ríos Rubén Marcelo.
Debería devolver algo como
{
"SPEAKER_11": "Ríos Rubén Marcelo"
}
Idealmente se debería poder envíar toda la transcripción entera y que devuelva todos los nombres pasibles de ser deducidos de esta forma. Se intentó hacer esto con los modelos de Llama 3.1 8b, 70b, Llama 3.2 1b y GPT4o, todos fallando en la tarea por un margen de error muy alto. En algunos casos por exceso de verbosidad (lo cual nos hizo pasar a usar Instruct) y en otros por simplemente respuestas equivocadas.
También intentamos usar modelos BERT utilizando SPEAKER_XX como máscara, pero en ningún caso pudimos obtener un resultado correcto. Problablemente se pueda entrenar un modelo BERT que sea muy rápido y poco demandante especializado en esta tarea, pero esto requeriría un dataset muy grande y de alta calidad.
Creemos que el siguiente flujo debería ser posible y completamente automatizable en un futuro cercano con hardware disponible al consumidor, si es que no es posible ya
Una validación humana en cualquier caso siempre es necesaria y moralmente correcta.
Creación de los podcasts
Para los podcasts en Inglés se utilizó la herramienta gratuita (por el momento) de NotebookLM de Google.
Luego usando whisperx se transcribieron de la misma forma comentada en esta página
Finalmente, se usó ChatGPT 4o para que cree una traducción con expresiones argentinas, puesto que si bien whisper es capaz de generar una traducción, lo hace en una forma neutra.
Para la síntesis de voz en Español se usó la interfaz gradio de F5-TTS con el modelo F5-Spanish hosteado localmente en una RTX 3090 que logra sintezar a razón de tiempo de 1:1 (1 minuto de procesamiento sintetiza 1 minuto de voz, aproximadamente).
Las voces se obtuvieron de recortes de actores profesionales que son parte del repertorio de voces de elevenlabs.io. Si bien no se usó ElevenLabs para la sintesis de las voces, sí se usaron algunos recortes generados por la página como voz de referencia para F5-TTS y de acuerdo a su política de copyright, es necesario acreditarlos como dueños de dichas producciones en casos no comerciales como los de esta página.